网络IO模型
背景知识
在深入的去了解和学习 IO 模型时,是要求对操作系统的一些底层概念是要了解的,比如 VFS树、FD、Page Cache、Dirty Page、Flush 等。这些概念到时候我会再学习一下,然后单独去写一篇操作系统关键性概念的文章。另外,在学习 IO 的时候,TCP/IP 协议也是需要了解的,包括三次握手以及 linux 中在建立连接时的系统调用信息,这对于理解 IO 很有帮助。
C10K 问题
C10K 问题介绍
线程是 CPU 调度的最小单位,进程是 CPU 分配资源的最小单位
C10K 是一个经典的服务端问题。最初的服务器是基于进程/线程模型,新的一个 TCP 连接,就需要分配一个进程(或者线程),如果有 10k 个连接,那么需要创建 1w 个进程(或线程),对于单机服务器来说,这是无法承受的。所以如何去突破单机的性能,是高性能网络编程必须要面对的问题。关于 C10K 问题的探讨,可以参考这篇文章 The C10K problem.
解决方案
从 C10K 的背景中看出,要向解决高并发的连接问题,无非有两种,一是一个连接一个线程,另一个是多个连接一个线程。前者会因为系统资源而限制,就算系统资源充足,实际上效率也并不高,会涉及到大量的线程上下文切换操作,扩展性差,后者是现在的主流处理方式。
同步与异步
在涉及到 IO 问题时,通常会聊到同步与异步的概念,所谓的同步异步是在于应用程序读写数据还是内核来读写数据,如果说读操作是应用程序来读(调用 read() 的 system call 方法),写操作是应用程序来写(调用 write() 的 system call 方法),那么这种模型就是同步的;如果是内核来做的读写,那么就是异步的。实际上,在目前的 linux 内核版本(2.6)是没有异步的实现,只有 Windows 实现了异步模型。
阻塞与非阻塞
阻塞与非阻塞也是 IO 中经常容易混淆的概念,应用程序在发起读写操作时,对应就是某一个线程发起读写操作,那么会通过系统内核来进行 IO 操作,发起读写操作的线程如果一直等待内核 IO 操作完成以后,才能执行其他的操作,那么这种模型就是阻塞的,如果不需要等待内核 IO 操作完成,可以直接进行后续的操作,此时内核会立即返回给线程一个状态值。那么这种模型就是非阻塞的。
综上所述,IO 模型可以分为四类,同步阻塞、同步非阻塞、异步阻塞、异步非阻塞,实际上异步阻塞 是没有意义的。所以目前 IO 主要分为三大类,而 Linux 只有前两类的实现,只有 Windows 实现了异步非阻塞的模型。接下来再了解一下同步阻塞和同步非阻塞的 IO 模型。
IO 模型
系统环境:CentOS 7.9,内核版本是 2.6
JDK 版本:11
- BIO(同步阻塞)
BIO(Blocking IO) 也是常说的传统 IO,java 中的实现在java.io包中。对于 BIO 的模型,从 linux 内核角度来说就是一个 TCP 连接就新建一个 thread 去处理,在很高的并发连接下,对于系统资源的开销还是比较大的。另外对于数据的读写,都必须要等到内核 IO 操作完成以后,在等待的过程中,线程一直占用资源,利用率不高。看一个 java BIO 的例子。
1 | public class SocketBio { |
编译后在linux上跑一下(我的linux内核版本是 2.6),用linux工具命令strace 来跟踪该 java 进程的系统调用情况,运行:strace -ff -o out java top.caolizhi.example.io.bio.SocketBio
跟踪的日志输出到 out 文件中。
服务端开始启动,并且阻塞在 accept 代码段,输出:
我们看到有很多 out.pid 格式的文件产生,如下图所示,最小的 pid 是主进程,还有垃圾回收进程等,应该都是 fork 出来的子进程。

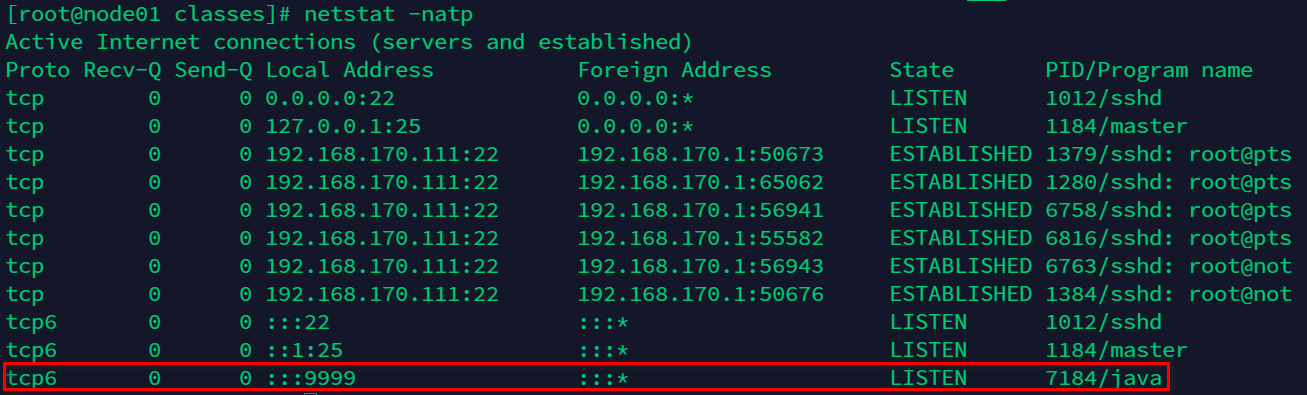
再来看一下服务端打开的TCP端口监听,执行命令netstat -natp
可以看到 java 进程的 pid 是 7184,然后当前的状态是 LISTEN 状态
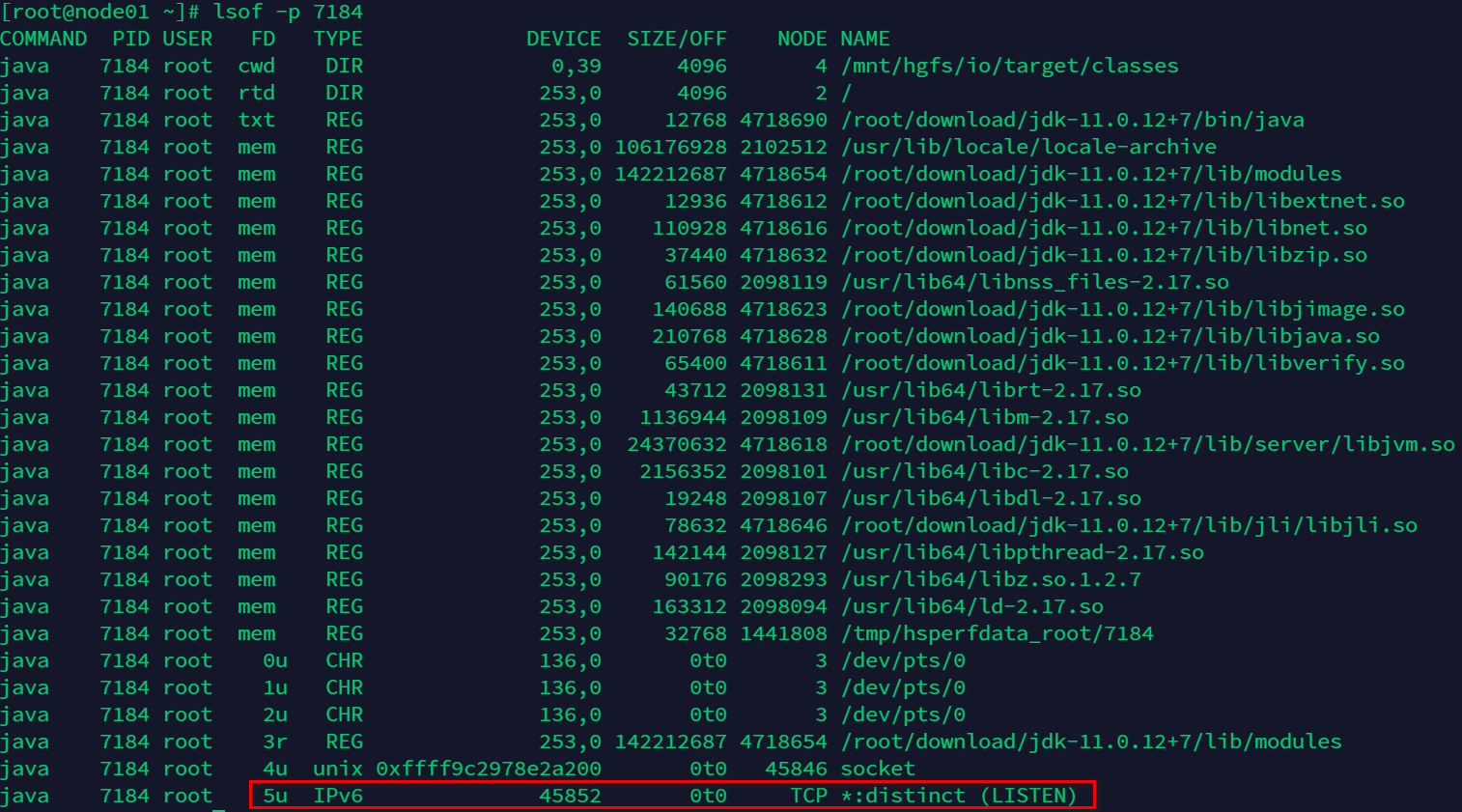
再来看一下 7184 这个进程打开 FD(File Descriptor 文件描述符)有哪些,执行命令:lsof -p 7184lsof命令是查看当前系统文件的工具,一切皆文件,我们查看的是 java 进程打开了哪些文件(FD),如图:
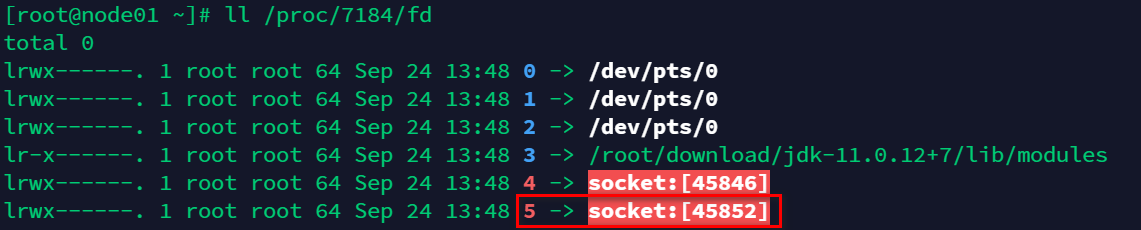
还可以看一下 java 进程 socket 的信息,执行命令:ll /proc/7184/fd
看到当前打了一个 fd = 5 的 socket,与 lsof 的结果一致。
看了 java 进程打开的 FD 之后,接来下就看一下 java 进程 7184 的系统调用日志,打开 out.7184,主要看到最后几行的片段:
1 | stat("/etc/sysconfig/64bit_strstr_via_64bit_strstr_sse2_unaligned", 0x7fff49a171a0) = -1 ENOENT (No such file or directory) |
实际上,7184 的进程里面又 clone 了一个子进程 7185,我们再去 7185 这个进程里面看一下,在 7185 的进程里面有几个关键的系统调用:bind(),listen()
1 | bind(5, {sa_family=AF_INET6, sin6_port=htons(9999), inet_pton(AF_INET6, "::", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, 28) = 0 |
上面操作中,bind()把等于 5 的 FD 和端口 9999 绑定,listen监听 5 这个 FD。然后调用 write() 的系统调用把需要打印信息写到标准输入的FD 1。
最后是 poll() 和以前的 accept() 类似,阻塞等待。
实际上这里有点疑问,之前的系统调用是 accept 阻塞等待,但是现在变成了 poll
接下来,我们接入一个客户端,看一下是什么情况,执行命令:nc localhost 9999
看到有信息输出:

再来看一下 7184 fd 的情况:
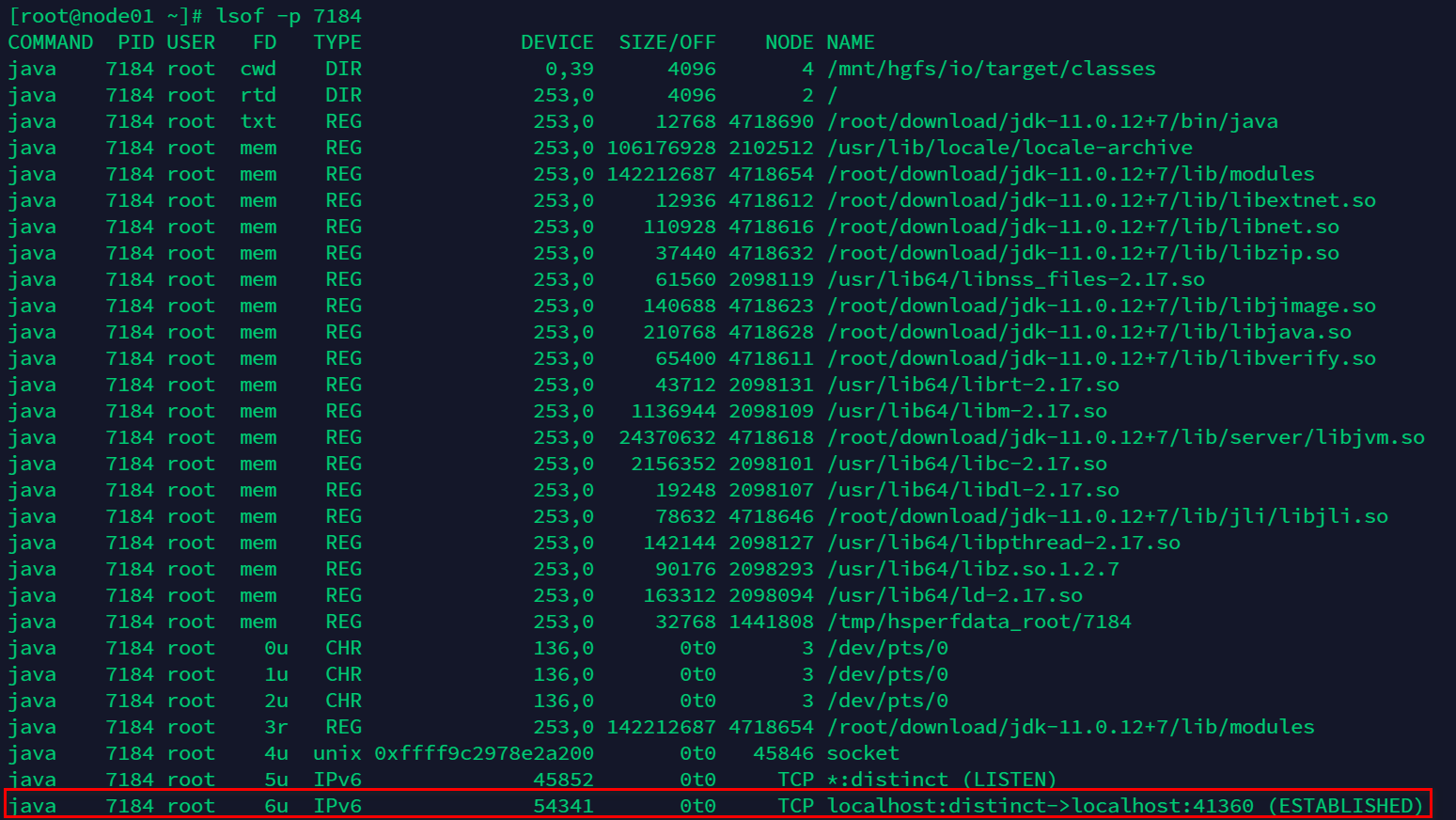
可以看到 fd = 6 的 socket 连接,状态为 ESTABLISHED。当有客户端连接以后,代码里面会新建一个线程来处理,我们得到了 out.7382 的日志:
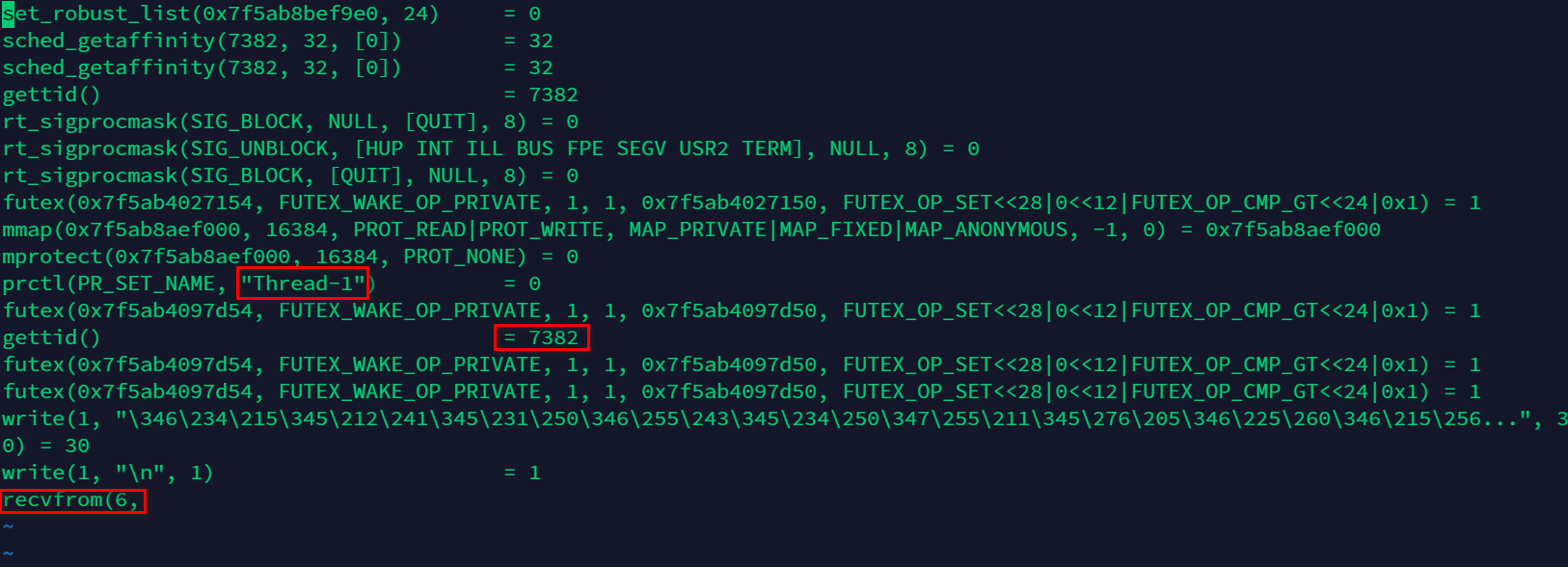
上图中,大概能看到 thread 的名称,pid 号, 还有系统调用 recvfrom(6,),等待接收数据。
以上就是一个 BIO 的底层实现流程,从上面的过程可以看到,服务端有两次阻塞,第一次是启动后等待客户端连接(accept),第二次是在客户端连接后等待客户端发送数据(recevfrom),如果没有数据,服务会一直阻塞住。另外如果我再开一个客户端连接,那么会新开一个线程去处理,大量的请求连接会造成服务器的压力。
另外我们可以还可以看一下客户端和服务端建立 TCP 连接的三次握手,四次挥手的过程,执行命令:tcpdump -nn -i ens33 port 999
过程如下:


- NIO(同步非阻塞)
针对 BIO 的劣势,我们考虑在单线程服务器处理,即我不去新建一个线程去处理,所有的请求在同一个线程里面处理,(其实这里你可以想一下 redis),但是这样会有一个问题就是一个连接请求进来了,线程阻塞住在等待客户端发送数据,如果另一个客户端连接过来,那么服务端无法处理,我们进行优化一下,可以这样去解决,如果等待数据的阻塞,还可以继续接收客户端的连接,再继续优化,如果等待数据时阻塞住了,那么我们遍历下一个 socket client,我们改进一下 BIO 的代码。上述代码中,server 端和 client 端都设置成非阻塞的方式,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public class SocketNio {
public static void main(String[] args) throws IOException, InterruptedException {
List<SocketChannel> clientList = new LinkedList<>();
final ServerSocketChannel socketChannel = ServerSocketChannel.open();
socketChannel.bind(new InetSocketAddress(9999));
socketChannel.configureBlocking(false); // 不设置,就是阻塞,调用 accept(),这里解决 BIO 的第一个阻塞
System.out.println("server started ..." + socketChannel.socket().getInetAddress() + ":" + socketChannel.socket().getLocalPort());
while (true) {
Thread.sleep(1000);
final SocketChannel client = socketChannel.accept();
if (null != client) {
client.configureBlocking(false); // 配置非阻塞,否则一直等待客户端的数据,这里解决 BIO 的第二个阻塞
System.out.println("client :" + client.socket().getInetAddress() + ":" + client.socket().getPort());
clientList.add(client);
}else {
System.out.println("waiting for connection ....");
}
final ByteBuffer byteBuffer = ByteBuffer.allocate(4096);
// 遍历客户端,读写数据
for (SocketChannel channel : clientList) {
System.out.println("read data from client " + channel.socket().getInetAddress() + ":" + channel.socket().getPort());
final int byteNum = channel.read(byteBuffer);
if (byteNum > 0) {
byteBuffer.flip(); // 翻转,由写转成读
final byte[] readBytes = new byte[byteBuffer.limit()];
byteBuffer.get(readBytes); // 把 buffer 里面的数据 copy 到 readBytes 数组
final String data = new String(readBytes);
System.out.println(channel.socket().getInetAddress() + ":" + channel.socket().getPort() + "'s data :" + data) ;
}
}
}
}
}configureBlocking(false),并且将连接放在一个list集合中,在等待客户端消息时,看看消息是否准备好,遍历 list 集合,如果有消息则打印出来。我们可以再来看一下在启动服务的时候,第一次设置成阻塞模式的系统调用,同样是执行:strace -ff -o out java top.caolizhi.example.io.nio.SocketNio
如下图,可以看到 server 端阻塞住了:

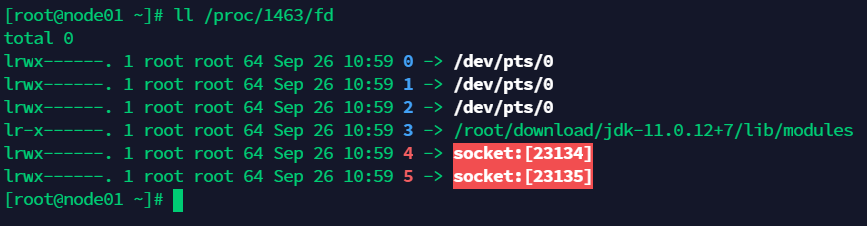
out.pid 找到 java 进程 fork 出来的监听子进程,1463,查看 1463 的 socket fd,如下:
再来看一下系统调用:
1 | write(1, "server started .../0:0:0:0:0:0:0"..., 39) = 39 |
看,看到了吧,调用 accept(4,) 一直在监听 fd = 4 ,等待客户端连接,我们看一下 accept 的方法:
1 | int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);; |
accept 系统调用目的就是等待一个 socket connection,这也印证了 BIO 的模型。
把 server 端和 client 端全部设置成非阻塞模式,运行:
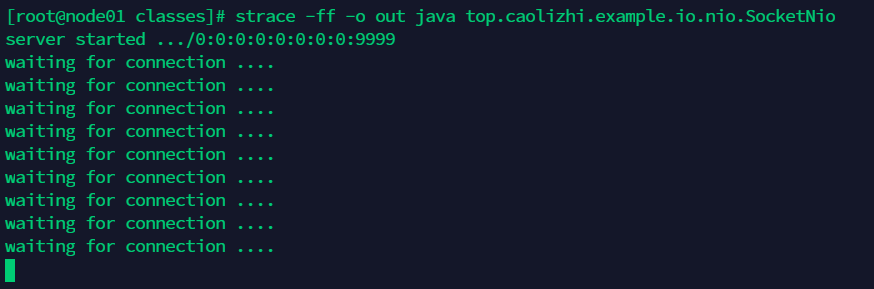
一直在循环等待 client 连接,现在打开一个 client 去连接server,同样执行nc 127.0.0.1 9999
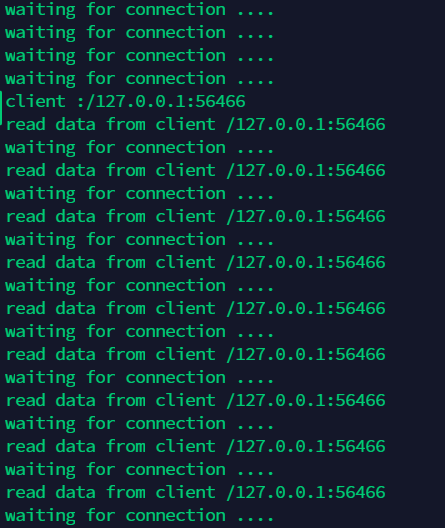
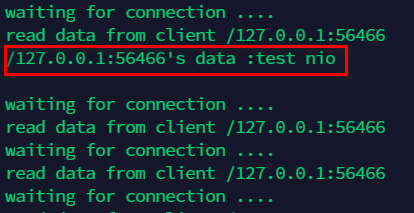
再来发送一组数据,比如”test nio”,我们可以看到 server 端接收到了数据打印了出来:
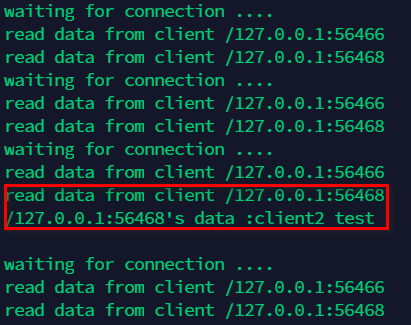
再开启一个客户端来连接服务端,发送数据”client2 test”,服务端如下图:
最后看一下 NIO 的系统调用片段:
1 | socket(AF_UNIX, SOCK_STREAM|SOCK_CLOEXEC|SOCK_NONBLOCK, 0) = 3 |
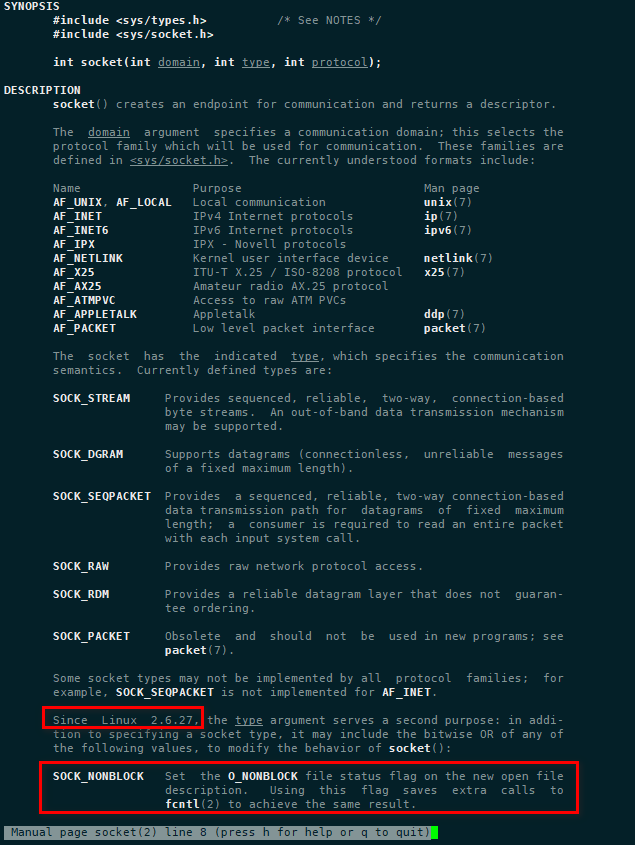
可以看到 socket 调用使用 SOCK_NONBLOCK 方式,另外,每一次调用 accept() 都会返回一个状态码,-1 表示没有连接可用。用man 2 socket来看一下描述:
综上所述,在非阻塞模式下,解决了 BIO 的两次阻塞,但是非阻塞也有弊端,我每一次都要循环遍历所有的 socket 连接,才能看到是否有消息发送,如果有大量的连接的话,显然效率是极低的。况且并不是所有的连接都是有消息的,每次仍然轮询的那些连接,也是不合理的。
那么,NIO 中,java 程序一直在轮询所有的连接,不断地在用户态和内核态切换,如果,把轮询放到内核中去做,那岂不是效率要高的多,这就引出来多路复用的模式。
- 多路复用(同步非阻塞)
首先理解一下多路复用的概念,”多路” 实际上指的就是多个 IO,多个 socket 连接,也就是说单个线程通过记录跟踪每一个 IO 的状态,来同时管理多个 IO。IO 多路复用的实现主要有三种,按照出现的时间顺序为:select,poll,epoll。- select
select 可以传入一个 fd 数组,内核需要开辟空间来存这部分 fd,然后去轮询,就算有数据也只是修改状态,然后全部返回给应用,并不会告诉应用那些 IO 是有数据的,所以应用还是要轮询一次,找有变化的 IO,再调用 read 取读取数据。所以这样就会有 2 次轮询和 2 次数据拷贝,另外 select 只支持最大 1024 个 fd,另外 select 是线程不安全的。 - poll
其实 poll 跟 select 差不多,但是可以支持任意个 fd,没有 1024 大小的限制,但是会受到系统文件描述符的限制,可用命令ulimit -a查看系统的限制。可以看下POLL方法描述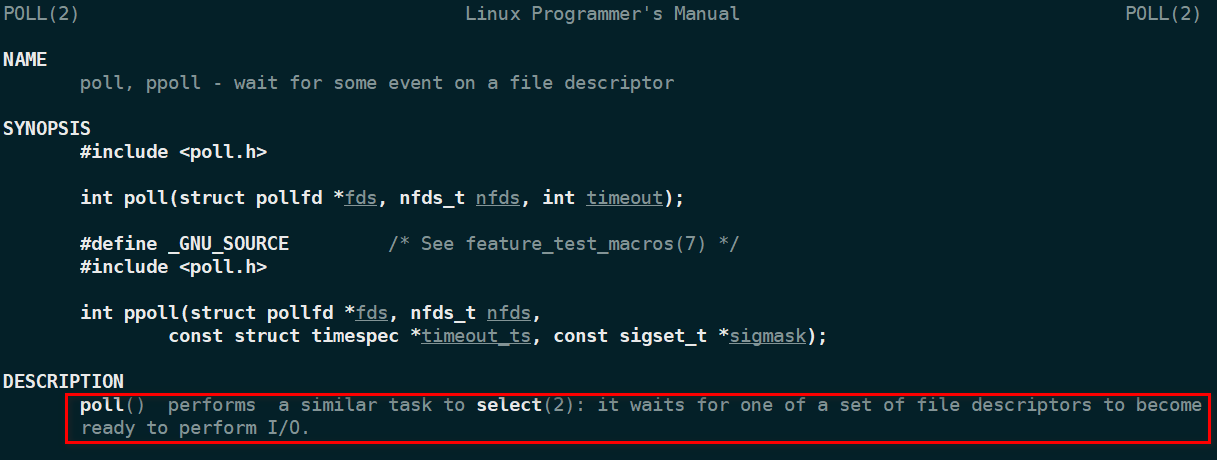
- epoll
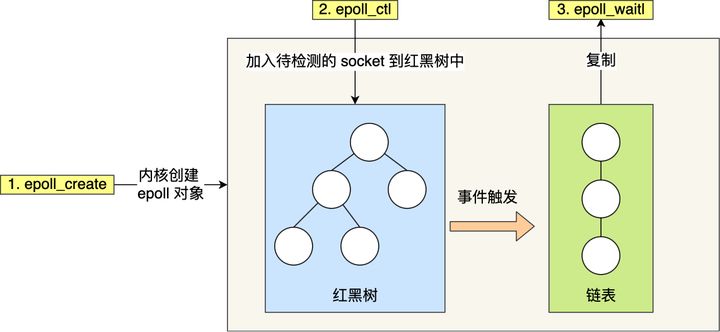
epoll 是最新的 IO 多路复用的实现,linux 内核 2.6 以后才出现。epoll 做了两件事情,第一件事就是,在内核中,使用红黑树来维护所有的需要检查的 fd,红黑树的时间复杂度是 O(logN),另外一件事就是使用了事件驱动机制,在内核中维护了一张链表,把有状态的 fd 都放到那个链表里面,应用直接来取有状态的 fd 集合,效率大大的提高。epoll(7) 的方法调用又分为三个系统调用,epoll_create,epoll_ctl,epoll_wait。- 应用调用
epoll_create方法会在内核开辟一个红黑树结构,返回一个 fd - 应用调用
epoll_ctl方法传入需要监听的 fd 和针对该 fd 相应的事件,是读还是写等?那么内核会不断地轮询该 fd,看是否有状态变化 - 应用程序
epoll_wait方法,内核会返回一个链表,链表里面是有状态变化的 fd,应用程序再去遍历这些 fd,调用read()或write()进行操作链表里面的 fd 是从中断处理那边产生的,网卡中断会把 fd 放到 fd buffer 里面,然后内核再把 fd buffer 里面的 fd 添加到红黑树,接着把有状态变化的 fd 放到链表里面。
- 应用调用
- select
接下来,再来看一个 java 多路复用的例子,代码如下:
1 | public class SocketMultiplexing { |
上面的例子根据注释能够看懂做了什么事情,不再详述,运行该程序:strace -ff -o out java top.caolizhi.example.io.multiplexing.SocketMultiplexing

一开始服务启动会得到一个监听的 fd,所以 total checking fd size 是 1。
根据 out.pid 文件看一下当前 java 进程的 fd,ll /proc/1931/fd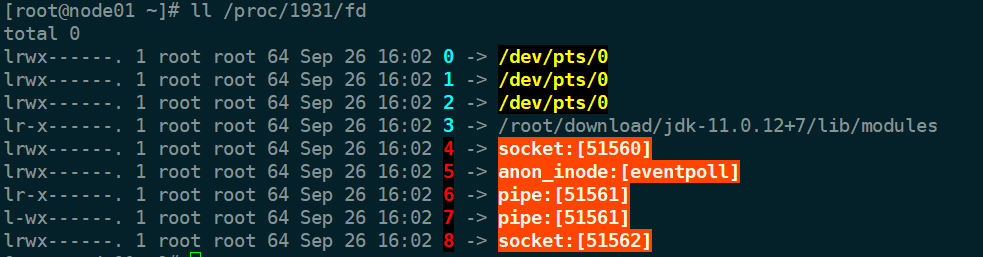
可以看到一个类型为 eventpoll 的 fd 5,还有两个 pipe 类型的 fd, 再用 lsof 命令执行一下:
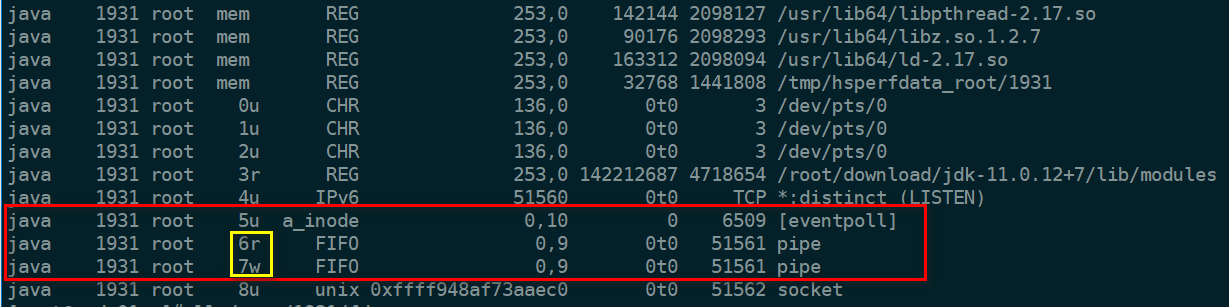
可以看到程序打开了一个类型为 eventpoll 的 fd 5 ,还有只能 write 的管道 fd 6以及只能 read 的管道 fd 7。
我们添加一个客户端来连接服务器,同样用 nc 命令,执行完后:
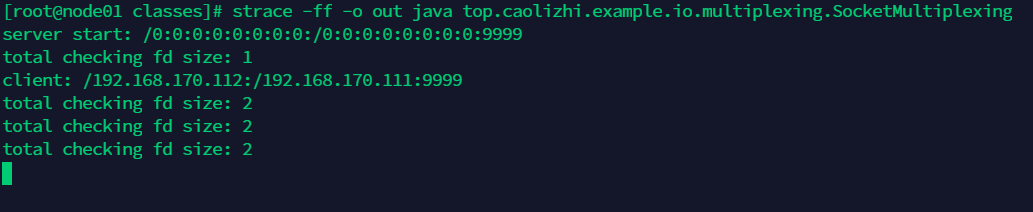
可以看到,当有客户端连接后,产生一个新的 socket fd,程序把这个新的 socket fd 调用 register 方法注册 READ 事件,那么此时total checking fd size 是 2。然后在客户端发送数据,”abc“,”dddd“,服务端也会回写同样的数据给客户端。如图: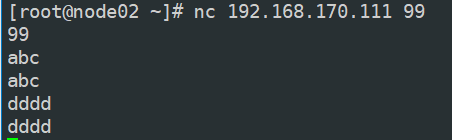
接下来整体看一下这个程序的系统调用追踪:
1 | 建一个 socket io,返回fd 4 |
另外,根据 epoll 的系统调用文档,又分为边缘触发和水平触发,这里不拓展了,有兴趣可以去看 man page 文档。
- AIO(异步非阻塞)
linux 内核是没有实现 AIO 的。它与同步非阻塞的区别在于,不需要一个线程去轮询 IO 的状态改变,而是一个 IO 的状态变更,系统会通知相应的线程来处理。JDK 中的 AIO 的底层实现也是基于epoll来实现的,并非真正的异步 IO。
参考
https://tech.meituan.com/2016/11/04/nio.html
https://notes.shichao.io/unp/ch6/
深入理解计算机操作系统

